


GraphQL es un nuevo estándar de API, que fue creado por Facebook, aunque fue lanzado como un proyecto de código abierto poco después, ha ganado mucha popularidad en los últimos tiempos por las ventajas que ofrece sobre REST, y muchas empresas están adoptando esta tecnología.
Ventajas ofrecidas por GraphQL sobre REST:
- Consultas con flexibilidad
- Permite especificar a los clientes exactamente que datos necesitan, mediante una sintaxis establecida, reduciendo la cantidad de endpoints y solicitudes http necesarias.
- Carga de datos
- Minimiza el problema de traer datos innecesarios en una consulta, o tener que traer datos de múltiples endpoints para reunir lo que necesitamos conseguir.
- Escalabilidad de la API
- Puedes extender el esquema fácilmente sin deprecar funcionalidades ya existentes.
- Estructura de datos
- La respuesta esta estructurada según la consulta enviada, ofreciendo exactamente los datos que fueron solicitados.
- La sintaxis de las queries es robusta y permite consultas avanzadas.
Framework utilizado
Para el desarrollo de esta API se utilizó Quarkus, lanzado por RedHat en 2019, es una alternativa a spring boot, que nos ofrece la posibilidad de compilar a código nativo, lo cual reduce considerablemente el tiempo de arranque y el uso de memoria de nuestra aplicación.
Compilar de manera nativa implica convertir nuestro código directamente en binario para el hardware donde se va a ejecutar, lo cual nos permite prescindir de la máquina virtual de java.
Esta tecnología está especialmente optimizada para entornos en la nube, con contenedores y serverless, donde nuestro proveedor de servicios se encarga de asignar los recursos, para ejecuciones de tareas a demanda, de esta manera usamos a nuestro favor la ventaja de requerir pocos recursos y tener un tiempo de arranque muy rápido.
Con enfoques más tradicionales, requeríamos tener infraestructura dedicada continuamente, por más que hubieran tiempos muertos, mientras que con esta tecnología, pagamos solo por los recursos que realmente usamos.
Como crear nuestro proyecto Quarkus
Si ya conoces como crear un proyecto Quarkus, haz click aquí , para pasar al siguiente titulo y empezar a ver la creación del API.
Generalmente nuestro IDE nos aprovisiona de algún plugin o herramienta para facilitarnos la creación de nuestro proyecto con Quarkus, si estamos usando VS Code, debemos instalar los siguientes plugins:
Una vez hecho esto debemos hacer CTRL + T y buscar el siguiente comando:
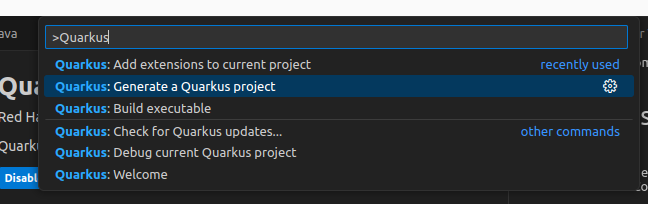
Al generar un nuevo Quarkus Project nos pedira una serie de datos, como la herramienta de compilación (Maven), la versión de java, groupId y nombre del artifact, pero lo más importante está al final, que es que modulos vamos a integrar al proyecto:
En este caso vamos a seleccionar SmallRye GraphQL, SmallRye GraphQL Client, H2 (para tener una base de datos en memoria de pruebas), Hibernate (Mapeador objeto relacional), una vez seleccionado todo damos ENTER, elegimos el directorio donde crearemos el proyecto.
Con el proyecto creado, nos posicionamos en el directorio donde fue creado, ejecutamos el siguiente comando (para abrir el vscode como superusuario):
sudo code . --no-sandbox --user-data-dir="/home/[TU-USUARIO]/vscode-root"
Si hicimos todo correctamente, tenemos un proyecto vacio con el POM ya generado.
Para levantar nuestro proyecto y probarlo debemos abrir un terminal en el IDE y ejecutar el siguiente comando:
./mvnw quarkus:dev
Esto nos levantara por defecto lo que tengamos codificado en el localhost:8080, si queremos cortar la ejecución es en la terminal con la letra q.
Ahora podemos proceder a agregar el código a nuestro proyecto.
Desarrollando nuestra api
Se hizo un API básica donde se almacenan libros con id, titulo y nombre del autor, este prototipo está disponible en github (en este enlace) Las operaciones disponibles son:
- Obtener todos los libros
- Agregar un libro
- Buscar libros que contengan una cadena string dada en su titulo
- Borrar un libro por id
- Actualizar un libro
A continuación tenemos la clase del modelo:
package model;
public class Book{
private String id;
private String title;
private String author;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public Book(String id, String title, String author) {
this.id = id;
this.title = title;
this.author = author;
}
public Book(){
}
}
A continuación tenemos el código de nuestra api GraphQL, donde se incluye una precarga de 3 libros, y los métodos correspondientes para las 5 operaciones que nombré antes.
package graphql;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.stream.Collectors;
import model.*;
import org.eclipse.microprofile.graphql.*;
@GraphQLApi
public class BookResource{
private List<Book> books = new ArrayList<>(Arrays.asList(
new Book("1", "Capitalismo y libertad", "Milton Friedman"),
new Book("2", "Código limpio: Manual de estilo para el desarrollo ágil de software", "Robert C. Martin"),
new Book("3", "Desenmascarando la mentira keynesiana: Keynes vs Hayek", "Javier Milei")
));
@Query("allBooks")
@Description("Get all books")
public List<Book> getAllBooks(){
return books;
}
@Mutation
public Book addBook(@Name("book") Book book){
books.add(book);
return book;
}
@Query
public List<Book> findBooksByTitle(@Name("titleContains") String titleContains){
return books.stream()
.filter(book -> book.getTitle().contains(titleContains))
.collect(Collectors.toList());
}
@Mutation
public Book deleteBookById(@Name("id") String id){
for(Iterator<Book> iterator = books.iterator(); iterator.hasNext();){
Book book = iterator.next();
if(book.getId().equals(id)){
iterator.remove();
return book;
}
}
return null;
}
@Mutation
public Book updateBook(@Name("id") String id,
@Name("title") String title,
@Name("author") String author) {
for (Book book : books) {
if (book.getId().equals(id)) {
if (title != null) {
book.setTitle(title);
}
if (author != null) {
book.setAuthor(author);
}
return book; // Retorna el libro actualizado
}
}
// Puede ser útil lanzar una excepción si el libro no se encuentra
throw new RuntimeException("Libro no encontrado con id: " + id);
}
}
Debemos configurar también un fichero JS, denominado apollo.config.js, el mismo debe estar ubicado al mismo nivel de la carpeta src en la estructura de directorios:
const environment = process.env.NODE_ENV || 'development';
const configs = {
development: {
service: {
name: 'my-graphql-service-dev',
url: 'http://localhost:8080/graphql',
},
includes: ['src/**/*.graphql'],
},
production: {
service: {
name: 'my-graphql-service-prod',
url: 'https://api.mi-servicio.com/graphql',
},
includes: ['src/**/*.graphql'],
},
};
module.exports = configs[environment];
Si observamos en el fichero js que configuramos, hay 2 urls que debemos setear, una para ambiente de desarrollo y otra para el de producción.
En este caso para pruebas, vamos a usar la del ambiente de desarrollos:
Para continuar, en nuestro brave o chrome debemos instalar la siguiente extensión:
Esto es un entorno que nos permite testear una api graphql, ejecutando sentencias sobre el endpoint.
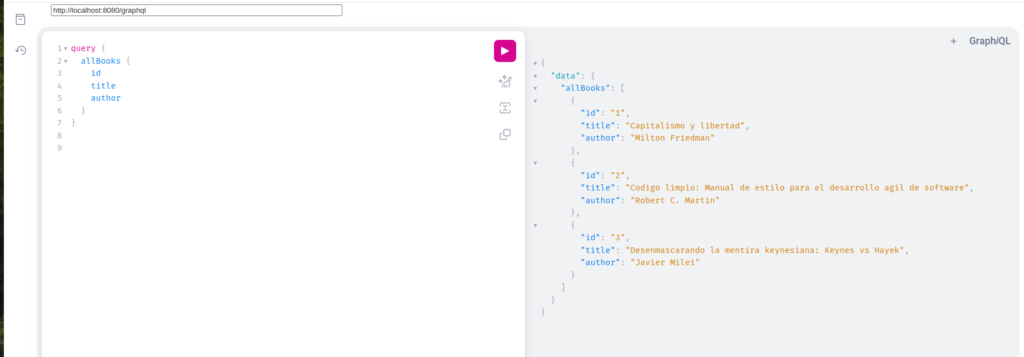
Si observamos en esa pantalla, debemos hacer copy paste sin diferencias de la url configurada en el apollo.config.js.
Ahi vemos como se escribió una query, la misma es ejecutada y obtenemos los resultados, que en este caso son los 3 libros precargados.
Sintaxis de graphql
Las sentencias dadas por este prototipo son las siguientes:
Obtener todos los libros
query {
allBooks {
id
title
author
}
}
Obtener un libro filtrando por una cadena string que este contenida en el titulo
query {
findBooksByTitle(titleContains: "keynes") {
id
title
author
}
}
Borrar un libro por ID
mutation {
deleteBookById(id: "1") {
id
title
author
}
}
Actualizar los datos de un libro
mutation {
updateBook(id: "2", title: "Clean Code Updated") {
id
title
author
}
}
Agregar un libro nuevo
mutation {
addBook(book: { id:"4", title: "Nuevo Libro", author: "Autor Desconocido" }) {
id
title
author
}
}
Conceptos de la sintaxis de graphql
Nuestra query siempre comienza eligiendo el tipo de operación, donde puede ser:
- query
- Esto es una lectura, nos puede devolver tanto un objeto individual como un listado.
- mutation
- Graphql introduce el concepto de mutación, que es básicamente cualquier escritura en la base (insertar, borrar, actualizar).
- subscription
- La suscripción es una operación que permite a los clientes suscribirse a eventos del servidor, para recibir notificaciones en tiempo real, de cambios en los datos.
- fragment
- Un fragment es un fragmento de código, que es denominado bajo un alias, y que puede ser reutilizado en distintas partes evitando así la repetición de código innecesaria.
En esta guía, solo me voy a centrar en Query y Mutation, Subscription y Fragment se verá en un próximo artículo.
Comprensión de la sintaxis de graphql
Query
Vamos a diseminar una sentencia de tipo query:
query {
findBooksByTitle(titleContains: "keynes") {
id
title
author
}
}
Esta es la consulta que trae a los libros, que contengan en el título la palabra “keynes”. Bajo la llave de query, especificamos la firma del método en la API que se encarga de esto, con los parámetros que lleve el mismo.
Luego abrimos llaves y se especifican los campos que se desean obtener, que en este caso fueron id, title y author.
Ahora bien, si observamos este método en la API podemos ver lo siguiente:
@Query
public List<Book> findBooksByTitle(@Name("titleContains") String titleContains){
return books.stream()
.filter(book -> book.getTitle().contains(titleContains))
.collect(Collectors.toList());
}
El mismo tiene una lógica para obtener los libros, usando la api de streams de java, convertimos la lista de libros en un stream, y aplicamos filtros (en este caso, solo uno), mediante sintaxis lamda especificamos el filtro para obtener los libros que se desean conseguir en la consulta.
Para finalizar, el stream resultante se transforma en una lista, para ser devuelta por el servicio.
Mutation
Siguiendo la misma linea conceptual, observamos la siguiente mutation, que es para agregar un libro:
mutation {
addBook(book: { id:"4", title: "Nuevo Libro", author: "Autor Desconocido" }) {
id
title
author
}
}
Primero elegimos cual de las 4 operaciones ejecutaremos, luego la firma del método, y para finalizar los campos que queremos devolver para confirmar que el registro fue insertado.
Un detalle final que quería acotar es, que nosotros podemos renombrar la firma del método, y los parámetros por medio de annotations.
Como lo es el caso de allBooks:
@Query("allBooks")
@Description("Get all books")
public List<Book> getAllBooks(){
return books;
}
En el caso de renombrar un parámetro, sería de la siguiente manera:
public List<Book> findBooksByTitle(@Name("titulo") String titleContains){